
Multi-label Classification of Coding Questions Using BERT and LSTM
For the CSC413 - Neural Network and Deep Learning I took this winter semester, I formed the team with my roommates Ethan and Thomas, and we chose the title as the focus for our final project, so in this post, I will briefly introduce the project and results.
Links to resources
We put all the resources and intermediate results in our github repo, and you can directly access the report here. Please see the abstract below for motivation and a very brief introduction of our work.

The core part is to use two models - BERT and LSTM to do the multi-label classification task, and we compared their performance and discuss the results.
Data Collection & Preprocessing
While we used data from Kaggle, it actually contains tens of columns of irrelevant information, and we cleared them out and only kept the title, description, and tags. After that, we record all tags appeared and turn the tags into 0-1 encodings for each question for the multi-label classification task - it is a necessary step for helping with neural network encoding.
Data Augmentation
Since there’re only 2000+ questions in the dataset, we decided to use data augmentation to increase the size of the dataset - mainly by translating engligh description into other languages and then translate back to english. We used google translate api for this task:
def translate_text(target, dest):
"""Translates text into the target language.
Target must be an ISO 639-1 language code.
See https://g.co/cloud/translate/v2/translate-reference#supported_languages
"""
import six
from google.cloud import translate_v2 as translate
translate_client = translate.Client()
if isinstance(text, six.binary_type):
text = text.decode("utf-8")
# Text can also be a sequence of strings, in which case this method
# will return a sequence of results for each text.
result = translate_client.translate(text, target_language=target)
return result
def transform(text):
# randomly select a language to translate to
lang = np.random.choice(['fr', 'zh-cn', 'es', 'de', 'ru', 'ja', 'ko'])
translated = translate_text(text, dest=lang)
# then translate back to english
translated = translate_text(translated, dest='en')
return translatedModel Architecture
Here is the archetecture of our BERT model:
class BERTClass(torch.nn.Module):
def __init__(self):
super(BERTClass, self).__init__()
self.bert = AutoModel.from_pretrained("microsoft/codebert-base")
self.fc = torch.nn.Sequential(
torch.nn.Linear(768, 512),
torch.nn.ReLU(),
torch.nn.Dropout(0.2),
torch.nn.Linear(512, num_labels)
)
def forward(self, ids, mask, token_type_ids):
_, features = self.bert(ids, attention_mask = mask, token_type_ids = token_type_ids, return_dict=False)
output = self.fc(features)
return output
model = BERTClass()
model.to(device)Here is the archetecture of our LSTM model:
input_layer = Input(shape=(max_len,))
embedding_layer = Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=128)(input_layer)
lstm_layer = LSTM(128)(embedding_layer)
output_layer = Dense(43, activation='sigmoid')(lstm_layer)
model = Model(inputs=input_layer, outputs=output_layer)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[my_accuracy], run_eagerly=True)Results
As we expected, the results show that BERT model outperforms LSTM model in terms of accuracy and F1 score, and we also did some analysis on the results and found that the LSTM model is more likely to predict the same label for all questions, while BERT model is more likely to predict the same label for all questions, which is a good sign for the BERT model.
Here are the results:
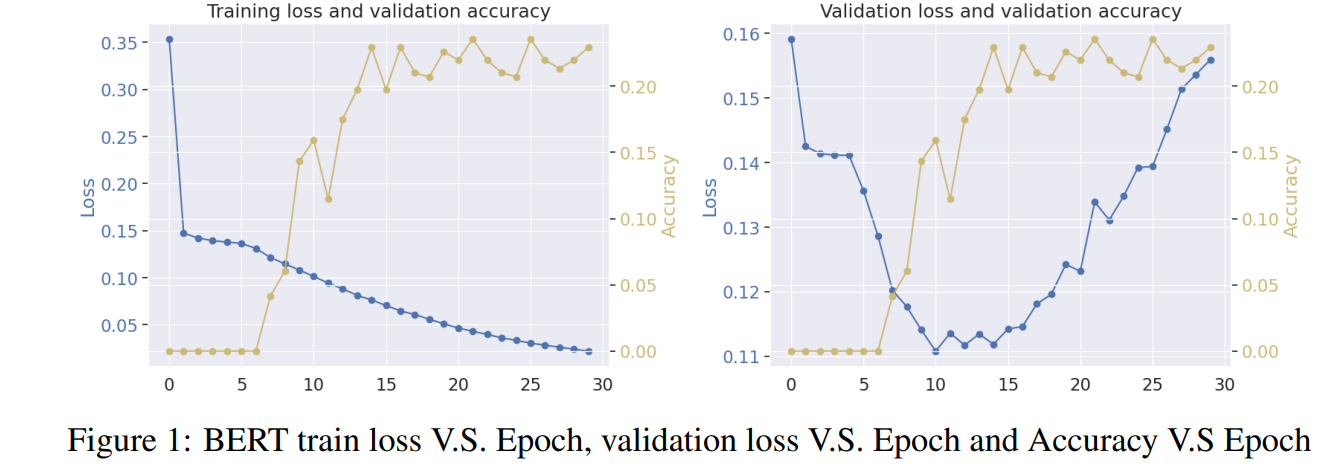
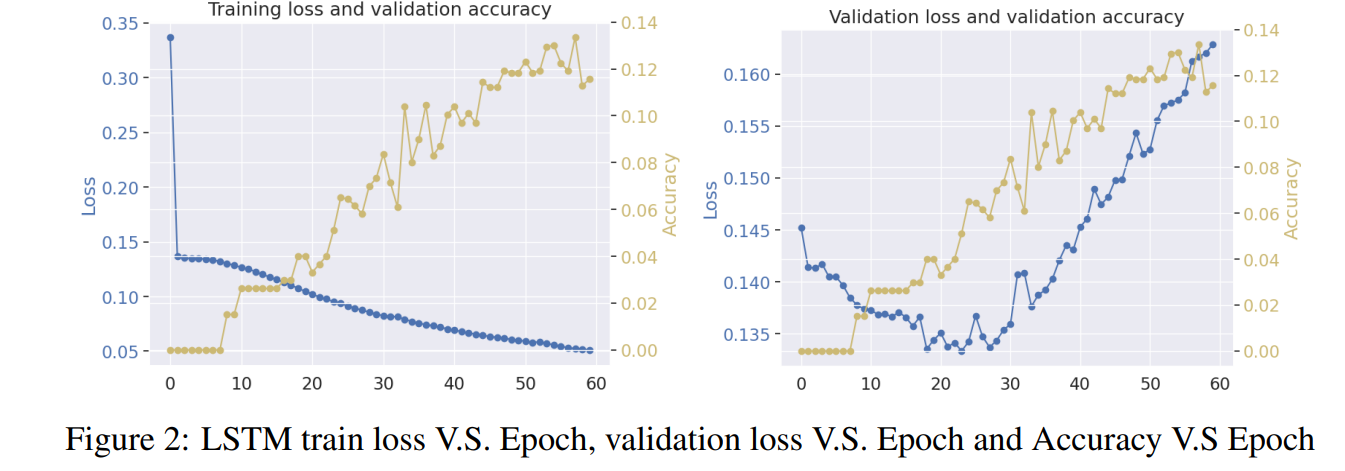
While this is not a very complicated project, it really helped me to practice building a neural network using the technique of “transfer learning” and “fine-tuning” from those mature archetectures like BERT, which is the core competency of taking CSC413 course.